
데이터베이스 관리 시스템(DBMS)의 성능을 논할 때 인덱싱(Indexing)은 결코 빠질 수 없는 주제다. 방대한 데이터를 다루는 환경에서, 원하는 데이터를 얼마나 빠르게 찾아낼 수 있느냐는 서비스의 품질을 결정짓는 척도와도 같다.
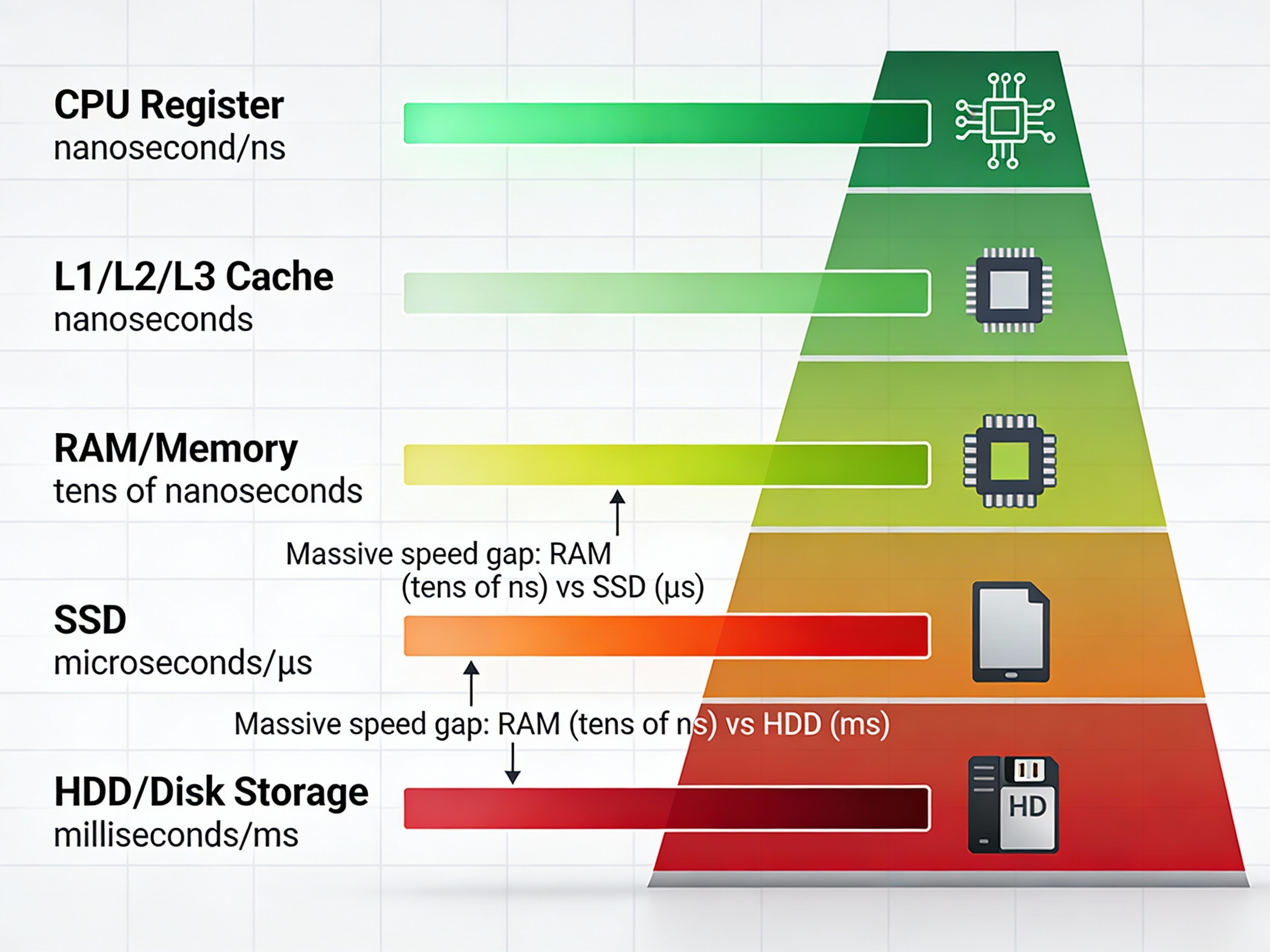
메모리(RAM)와 디스크(Storage)의 속도 차이는 여전히 거대하다. CPU 레지스터는 나노초(ns) 단위로 접근이 가능하지만, 메모리는 수십 나노초, SSD는 마이크로초(μs), 그리고 HDD는 밀리초(ms) 단위의 시간이 소요된다. 이 물리적 한계를 극복하기 위해 최소한의 디스크 I/O만으로 데이터를 탐색할 수 있는 자료구조가 필요했고, 그 해답의 중심에 B-Tree와 B+Tree가 있다.
B-Tree
정의 및 구조적 특징
B-Tree는 디스크와 같은 보조 기억 장치를 위해 고안된 균형 다진 탐색 트리(Balanced Multi-way Search Tree)다. 이진 탐색 트리(BST)가 자식 노드를 최대 2개만 가질 수 있는 반면, B-Tree는 한 노드에 M개의 자식을 가질 수 있다는 점이 가장 큰 차이점이다. 여기서 M은 차수(Order)를 의미한다.
이 구조가 왜 중요한가? 바로 '높이(Height)' 때문이다. 트리의 높이는 곧 최악의 경우 수행해야 할 디스크 I/O 횟수와 직결된다. 자식 노드를 많이 가질수록 트리는 옆으로 퍼지고(High Fan-out), 높이는 획기적으로 낮아진다.
핵심 제약 조건 (Invariants)
B-Tree가 균형을 유지하기 위해 반드시 지켜야 할 불변성 조건들은 다음과 같다 (M차 B-Tree 기준):
- Node Structure: 각 노드는 최대 M개의 자식을 가질 수 있다.
- Key Ordering: 노드 내의 모든 키는 오름차순으로 정렬되어야 한다.
- Root Node: 루트 노드는 자식이 아예 없거나(데이터가 0개), 2개 이상의 자식을 가져야 한다.
- Internal/Leaf Nodes: 루트를 제외한 모든 노드는 최소 ceil(M / 2)개의 자식을 가져야 한다. 즉, 노드가 최소 절반 이상은 채워져 있어야 공간 낭비를 막고 트리의 효율을 유지할 수 있다.
- Depth: 모든 리프 노드(Leaf Node)는 반드시 동일한 깊이(Level)에 존재해야 한다. 이는 B-Tree가 최악의 경우에도 O(log N)의 탐색 성능을 보장하는 근거가 된다.

작동 원리: 탐색, 삽입, 삭제
탐색 (Search)
탐색 과정은 이진 탐색 트리와 매우 유사하다. 루트에서 시작하여 찾고자 하는 키(Search Key)와 노드 내의 키들을 비교한다. 해당 키가 포함된 범위를 가리키는 포인터를 따라 하위 노드로 내려가는 방식이다. 이 과정은 리프 노드에 도달하거나 키를 찾을 때까지 반복된다.
삽입 (Insertion)과 분할 (Split)
B-Tree의 삽입은 항상 리프 노드에서 일어난다. 적절한 리프 노드를 찾아 키를 삽입하는데, 이때 노드가 가득 차 있어(Overflow) M-1개의 키를 초과하게 되면 노드 분할(Node Split)이 발생한다.
분할 메커니즘:
- 해당 노드의 키들 중 중간값(Median Key)을 선택한다.
- 중간값을 기준으로 노드를 왼쪽과 오른쪽 두 개의 노드로 분할한다.
- 중간값은 부모 노드로 승진(Promote)시킨다.
이 '승진' 과정이 B-Tree 균형 유지의 핵심이다. 승진으로 인해 부모 노드 역시 가득 차게 되면 연쇄적인 분할이 일어나며, 최종적으로 루트 노드가 분할될 때 비로소 트리의 높이가 1 증가한다. 즉, B-Tree는 위로 자라는(Bottom-up) 트리다.

삭제 (Deletion)와 병합 (Merge) / 회전 (Rotation)
삭제는 삽입보다 훨씬 복잡하다. 삭제 후 노드의 키 개수가 최소 조건(⌈M/2⌉ - 1) 미만이 되면 언더플로우(Underflow)가 발생하며, 이를 해결하기 위해 두 가지 전략을 사용한다.
- 재분배 (Redistribution / Rotation): 형제 노드에 여유 키가 있다면, 키를 빌려온다. 단순히 가져오는 것이 아니라, 부모 노드의 키를 내리고 형제의 키를 부모로 올리는 방식으로 회전이 일어난다. 트리의 구조를 크게 변경하지 않고 해결하는 효율적인 방식이다.
- 병합 (Merge): 형제 노드에도 여유가 없다면, 두 노드를 하나로 합친다. 이때 부모 노드에 있던 구분 키(Separator Key)를 가져와서 병합한다. 이는 부모 노드의 키 개수를 줄이므로, 부모 노드에서 다시 언더플로우를 유발할 수 있다(연쇄 병합 가능성).
B+Tree: 진화된 인덱스 구조
B-Tree의 한계와 B+Tree의 등장
B-Tree는 훌륭한 범용 인덱스 구조이지만, 데이터베이스 시스템, 특히 현대의 블록 기반 스토리지 엔진(Block-based Storage Engine)에는 2% 부족한 점이 있었다. 가장 큰 비효율은 모든 노드가 데이터를 가진다는 점이다. 내부 노드(Internal Node)에 데이터(Value 또는 Row ID)가 저장되면, 한 페이지(Page/Block)에 저장할 수 있는 키(Key)의 개수가 줄어든다. 이는 트리의 높이(Height)를 높이는 요인이 된다.
DBMS의 인덱스 크기는 수 기가바이트를 가볍게 넘긴다. 인덱스 전체를 메모리에 올리는 것은 불가능하므로, 자주 찾는 내부 노드(Internal Node)만이라도 최대한 메모리(Buffer Pool)에 올려야 한다. B+Tree는 바로 이 점을 파고들었다.
B+Tree의 핵심 아키텍처
B+Tree와 B-Tree의 결정적 차이는 두 가지다.
1. 인덱스와 데이터의 완전한 분리
B+Tree의 모든 내부 노드는 오직 라우팅(Routing) 역할만 수행한다. 실제 레코드에 대한 포인터나 값은 오직 리프 노드(Leaf Node)에만 저장된다.
- Fan-out 극대화: 내부 노드에서 데이터 공간을 제거함으로써, 한 페이지에 더 많은 Key를 저장할 수 있다. 예를 들어, 4KB 페이지에 Key(8B)+Pointer(8B) 조합이라면 약 250개의 자식을 가질 수 있다. 차수(M)가 커지면 트리의 높이는 기하급수적으로 낮아진다.
- Buffer Pool 효율: 내부 노드의 밀도가 높아지므로, 적은 메모리로도 더 넓은 범위의 인덱스를 캐싱할 수 있다.
2. 리프 노드 간의 연결 (Linked List)
모든 리프 노드는 키 순서대로 정렬되어 있으며, 양방향 연결 리스트(Doubly Linked List)로 이어져 있다.
- Range Scan 최적화: B-Tree에서는 범위 검색 시(예:
BETWEEN 10 AND 100) 계속 부모-자식을 오가는 탐색(Traverse)이 필요했다. 반면 B+Tree는 시작점만 찾으면(Random Access 1회), 그 뒤로는 연결 리스트를 타고 쭉 긁으면 된다(Sequential Access). - Sequential I/O: 디스크는 랜덤 읽기보다 순차 읽기가 압도적으로 빠르다. B+Tree의 리프 노드 순회는 디스크 헤드의 이동을 최소화한다.

B-Tree vs B+Tree: 승자는?
데이터베이스 인덱싱의 관점에서 비교해보자.
| 특성 | B-Tree | B+Tree | 승자 (DB 관점) |
|---|---|---|---|
| 데이터 저장 | 모든 노드에 분산 저장 | 리프 노드에만 저장 | B+Tree (높이 감소) |
| 트리 높이 | 상대적으로 높음 (낮은 Fan-out) | 매우 낮음 (높은 Fan-out) | B+Tree (I/O 최소화) |
| 풀 스캔 (Full Scan) | 모든 노드 탐색 필요 (Tree Traversal) | 리프 노드만 순차 탐색 (Linear Scan) | B+Tree (압도적) |
| 범위 검색 (Range) | 부모-자식 오가는 탐색 반복 | 리프 노드 링크 따라 순차 이동 | B+Tree (Sequential I/O) |
| 단건 검색 (Point) | 루트 근처에 데이터 있으면 빠름 | 무조건 리프까지 가야 함 | 무승부 (일관성은 B+가 우위) |
성능 심층 분석
1. 범위 검색 (Range Search)의 절대 강자
데이터베이스 쿼리의 상당수는 범위 검색이다. (DATE >= '2024-01-01', PRICE < 50000 등).
B-Tree에서 10개의 연속된 데이터를 찾으려면 트리를 최소 10번 오르내려야 할 수도 있다(Worst Case). 반면 B+Tree는 단 한 번의 트리 탐색으로 시작점을 찾고, 나머지는 옆으로 이동한다. HDD 기준으로 이는 수십 배의 성능 차이를 만들어낸다.
2. 캐시 히트율 (Cache Hit Ratio)
B+Tree의 내부 노드는 데이터가 없어서 매우 가볍다. 현대의 DB 서버는 수십 GB의 RAM을 Buffer Pool로 사용하는데, B+Tree 구조에서는 인덱스의 상위 레벨(Root ~ Branch) 거의 전부를 메모리에 상주실 수 있다. 실제 InnoDB 메트릭에서 buffer_pool에서 약 3억 건 이상의 읽기가 발생했지만, 상위 노드가 메모리에 있어 실질적인 디스크 I/O는 리프 노드 접근으로 제한된다. 이는 실질적인 디스크 I/O를 리프 노드 접근(1회)으로 제한하는 효과를 낳는다.
3. 단건 조회에서의 성능 차이
B-Tree의 이점: 찾는 키가 상위 레벨(내부 노드)에서 발견되면 즉시 데이터를 반환할 수 있다. 이론적으로 트리 높이 1~2 정도만 탐색해도 되는 경우가 있다.
B+Tree의 일관성: 반드시 리프 노드까지 내려가야 하므로, 트리 높이만큼 항상 일정한 I/O가 발생한다. 하지만 높이 자체가 매우 낮기 때문에(4GB 데이터에서 높이 3~4), 실무에서는 무시할 수 있는 수준의 차이다.
결론: 파일 시스템처럼 단건 접근이 주가 되는 곳에는 B-Tree도 쓰이지만, 대량의 데이터를 범위로 조회하고 통계 내는 데이터베이스(RDBMS) 환경에서는 B+Tree가 사실상의 표준(Default Standard)이다.
InnoDB 구현과 실무 최적화
InnoDB의 인덱스 물리 구조
MySQL의 InnoDB 엔진은 "모든 것은 B+Tree 인덱스다"라고 해도 과언이 아니다. InnoDB는 테이블 데이터를 저장하는 방식(Clustered Index)과 보조 인덱스(Secondary Index) 모두 B+Tree를 기반으로 한다.
1. Clustered Index (PK)
InnoDB 테이블은 프라이머리 키(PK)를 기준으로 정렬된 B+Tree 구조 그 자체다. 리프 노드에는 PK뿐만 아니라 Row의 모든 컬럼 데이터가 저장된다.
- 장점: PK로 조회 시 별도의 데이터 페이지 Lookup 없이 바로 데이터를 얻을 수 있다.
- 단점: PK가 변경되면 레코드의 물리적 위치가 이동해야 하므로 비용이 매우 크다. (따라서 PK 변경은 지양해야 한다)
2. Secondary Index
보조 인덱스의 리프 노드에는 인덱스 키 값과 PK 값이 저장된다.
- 동작: 보조 인덱스 탐색 → PK 획득 → Clustered Index 탐색(PK Lookup) → 데이터 획득.
- 커버링 인덱스(Covering Index): 만약 쿼리가 커버링 인덱스(인덱스 컬럼 + PK 만으로 해결 가능)라면, Clustered Index 탐색을 생략할 수 있어 성능이 비약적으로 향상된다. 예를 들어,
SELECT user_id, email FROM users WHERE email = 'test@example.com'라는 쿼리에서(email, user_id)복합 인덱스를 만들면 email 인덱스 리프 노드에서만 데이터를 완성할 수 있다.

UUID PK
1. UUID 선택 전략: v4 vs v7
개발의 편의성 때문에 UUID를 PK로 사용하는 경우가 있다. 하지만 UUID 버전 선택이 성능을 결정한다. B+Tree 구조에서 UUID v4(완전 랜덤)는 성능에 치명적이지만, UUID v7(시간 정렬 가능)은 AUTO_INCREMENT에 준하는 성능을 제공한다.
UUID v4의 문제 - 완전 랜덤 삽입:
- 새로운 데이터가 B-tree의 임의 위치에 삽입
- PostgreSQL/MySQL이 무조건 페이지 분할 실행
- 인덱스 단편화(Fragmentation) 발생
- 페이지 분할 폭증: AUTO_INCREMENT 대비 2~3배 증가
- 인덱스 크기 22% 증가
- 삽입 성능 약 35% 저하
UUID v7의 혁신 - 시간 기반 정렬:
- 구조: 48비트 Unix 타임스탬프(밀리초) + 12비트 서브ms 카운터 + 62비트 랜덤
- 시간순 정렬: 새로 생성되는 ID가 항상 시간 순서대로 증가 (단조성 보장)
- 순차 삽입: 트리의 오른쪽 끝에만 데이터 추가 (페이지 분할 극소화)
- 성능 개선 수치 (PostgreSQL 벤치마크):
- 삽입 성능 34.8% 빠름 (v4 대비)
- 인덱스 크기 22% 더 작음 (v4 대비)
- 디스크 사용량 175 MB 감소 (1000만 행 기준)
- Point lookup 1.78배 빠름 (0.129ms vs 0.230ms)
- 버퍼 히트 수 33배 증가 (3회 vs 101회) - 캐시 효율성 극적 개선
UUID v7 채택 현황:
- PostgreSQL 18부터 공식 지원
- RFC 표준화 진행 중 (사실상의 신규 표준)
- 글로벌 유니크 + 시간 정렬 + ID 관리 불필요
권장: UUID를 사용해야 한다면 반드시 v7을 선택할 것. v4는 절대 금지.
2. 분산 시스템에서의 ID 생성 전략
단일 DB에서는 AUTO_INCREMENT가 최고지만, 분산 시스템에서는 새로운 선택지들이 있다. 각 전략은 독립적인 ID를 생성할 수 있으면서도 중앙 조정자 없이 전역 유니크를 보장한다.
Snowflake ID
- 구조: 타임스탬프(41비트, ms) + 워커ID(10비트) + 시퀀스(12비트)
- 저장: 64비트 정수 (매우 컴팩트)
- 특징: 시간순 정렬 가능
- 처리량: 초당 최대 409.6만 건 (워커당 4096개 시퀀스 × 1000ms)
- 단점: 워커 ID 수동 할당 필수 (확장 시마다 관리 필요), 1024개 워커 제한
- 사용 사례: Twitter, Discord 등 대규모 서비스
TSID
- 구조: 타임스탬프(42비트) + 랜덤(22비트)
- 특징: Snowflake + ULID의 장점 결합
- 저장: 64비트 정수 or 13자 문자열 (매우 짧음)
- 확장: 워커 ID 자동 생성 (수동 할당 X) - 확장성 최고
- 보안: 워커 ID 숨김 (프라이버시 우수)
- 중복 확률: 극히 희박 (랜덤 22비트)
- 추천: 고확장성 분산 시스템
UUID v7 (최신 표준)
- 구조: 타임스탬프(48비트) + 서브ms 카운터(12비트) + 랜덤(62비트)
- 특징: 라이브러리 불필요 (DB 자체 지원)
- 표준: RFC 표준화 진행 중
- 이점: 글로벌 유니크+ 시간정렬 + ID 관리 불필요
- 단점: 128비트 (저장 오버헤드 있음)
- 추천: PostgreSQL 18+, MySQL 8.0.36+
| 특성 | Snowflake | TSID | UUID v7 |
|---|---|---|---|
| 비트 | 64 | 64 | 128 |
| 구조 | ts(41) + workerID(10) + seq(12) | ts(42) + random(22) | ts(48) + counter(12) + random(62) |
| 저장 크기 | 8B 정수 | 8B 정수 or 13자 | 16B or 36자 |
| 시간순 정렬 | ✓ | ✓ | ✓ |
| 워커 관리 | 필수 | 자동 | 불필요 |
| 확장성 | 1024 워커 제한 | 무제한 | 무제한 |
| 중복 가능성 | 없음 | 극히 희박 | 거의 무 |
| 도입 난이도 | 중간 | 중간 | 낮음 (DB 지원) |
선택 기준:
- 단일 DB? → AUTO_INCREMENT (가장 간단)
- 분산 시스템 + PostgreSQL 18+ or MySQL 8.0.36+? → UUID v7 (신규 표준, 구현 간단)
- 분산 시스템 + 구형 DB 버전? → TSID (최고의 선택지, 자동 확장)
- 매초 수백만 건 처리 필요? → Snowflake ID (트위터 검증)
- 금융/결제 도메인 (중복 제로)? → Snowflake ID (아주 희박한 중복도 불허용)
3. 페이지 크기와 인덱스 깊이
InnoDB의 기본 페이지 크기는 16KB다. 키(Key) 크기가 작을수록 한 페이지에 더 많은 키를 넣을 수 있고(High Fan-out), 트리의 높이(Depth)를 낮게 유지할 수 있다. 불필요하게 긴 VARCHAR를 인덱스로 잡는 것은 피해야 한다.
예시 계산:
- VARCHAR(10) 인덱스: 4KB 페이지에 약 256개 자식 가능
- VARCHAR(100) 인덱스: 4KB 페이지에 약 40개 자식 가능
- 높이 3일 때: 256³ ≈ 1,600만 row vs 40³ ≈ 6.4만 row
4. Range Query와 커버링 인덱스의 중요성
B+Tree의 리프 노드 연결은 범위 쿼리에서 진가를 발휘한다. WHERE created_at >= '2024-01-01' AND created_at < '2024-02-01'와 같은 쿼리는 범위 시작점을 찾은 후, 리프 노드 체인을 따라 선형으로 이동하기만 하면 된다.
중요한 것은 커버링 인덱스를 설계하는 것이다. 예를 들어:
SELECT user_id, email, created_at
FROM users
WHERE created_at >= '2024-01-01'
ORDER BY created_at;이 쿼리를 위해 (created_at, user_id, email) 복합 인덱스를 만들면:
- created_at 범위 탐색
- 리프 노드 체인 순회로 모든 필요 데이터 획득
- Clustered Index lookup 불필요
이는 2~3배 이상의 성능 향상을 가져온다.
PostgreSQL vs MySQL의 인덱싱 철학
PostgreSQL과 MySQL은 근본적으로 다른 인덱싱 구조를 가진다.
MySQL InnoDB: Clustered Index 방식
- PK가 곧 테이블 (B+Tree의 리프 노드 = 전체 행 데이터)
- PK 조회: 1단계 (PK 인덱스에서 완성)
- Secondary Index 조회: 2단계 (인덱스 탐색 → PK 이용해 Clustered Index 탐색)
- 장점: PK 조회 성능 매우 빠름
- 단점: PK 변경 시 물리 위치 이동 비용 높음
PostgreSQL: Separate Index 방식
- 모든 인덱스는 TID(Tuple ID)를 저장하는 독립적 B-Tree
- PK 조회: 2단계 (PK 인덱스 → 테이블 페칭)
- Secondary Index 조회: 2단계 (동일)
- 장점: 유연한 인덱싱, PK 변경이 간단
- 단점: 모든 인덱스 조회가 2단계
참고 문헌
- MySQL 8.0 Reference Manual: InnoDB Architecture dev.mysql
- PostgreSQL UUID v7 Performance Benchmarking (2025) dev
- Percona Blog: InnoDB Page Merging and Page Splitting percona
- PostgreSQL vs MySQL: Indexing Options Comparison bytebase
- PostgreSQL 18 UUID v7 Support betterstack